Robots.txt : Qu'est-ce que c'est et comment ça marche ?
Qu'est-ce qu'un fichier robots.txt ?
Robots.txt est un court fichier texte qui indique aux robots d'exploration (par exemple, Googlebot) ce qu'ils sont autorisés à explorer sur votre site Web.
Du point de vue du référencement, robots.txt aide à explorer les pages les plus importantes en premier et empêche les bots de visiter les pages qui ne sont pas importantes.
Voici à quoi peut ressembler le fichier robots.txt :

Où trouver robots.txt
Trouver des fichiers robots.txt est assez simple - allez sur n'importe quelle page d'accueil de domaine et ajoutez "/ robots.txt" à la fin de celui-ci.
Il vous montrera un vrai fichier robots.txt fonctionnel, voici un exemple :
https://votredomaine.com/robots.txtLe fichier Robots.txt est un dossier public qui peut être vérifié pratiquement sur n'importe quel site Web - vous pouvez même le trouver sur des sites tels qu'Amazon, Facebook ou Apple.
Pourquoi le fichier robots.txt est-il important ?
Le but du fichier robots.txt est d'indiquer aux robots d'indexation à quelles parties de votre site Web ils peuvent accéder et comment ils doivent interagir avec les pages.
De manière générale, il est important que le contenu du site Web puisse être exploré et indexé en premier - les moteurs de recherche doivent trouver vos pages avant qu'elles ne puissent apparaître comme résultats de recherche.
Cependant, dans certains cas, il est préférable d'interdire aux robots d'exploration de visiter certaines pages (par exemple, pages vides, page de connexion à votre site Web, etc.).
Ceci peut être réalisé en utilisant un fichier robots.txt qui est toujours vérifié par les robots d'exploration avant qu'ils ne commencent réellement à explorer le site Web.
Remarque : Le fichier Robots.txt peut empêcher les moteurs de recherche d'explorer, mais pas d'indexer.
Bien que les robots d'exploration puissent être interdits de visiter une certaine page, les moteurs de recherche peuvent toujours l'indexer si certains liens externes pointent vers elle.
Cette page indexée peut donc apparaître comme un résultat de recherche, mais sans aucun contenu utile – puisque les crawlers ne pourraient explorer aucune donnée de la page :

Pour empêcher Google d'indexer vos pages, utilisez d'autres méthodes appropriées (par exemple, la balise meta noindex) pour indiquer que vous ne souhaitez pas que certaines parties de votre site Web apparaissent dans les résultats de recherche.
Outre l'objectif fondamental du fichier robots.txt, il existe également des avantages SEO qui pourraient être utiles dans certaines situations.
1. Optimiser le budget de crawl
Le budget d'exploration détermine le nombre de pages que les robots d'exploration tels que Googlebot exploreront (ou réexploreront) au cours d'une certaine période.
De nombreux sites Web plus importants contiennent généralement des tonnes de pages sans importance qui n'ont pas besoin d'être fréquemment (ou pas du tout) explorées et indexées.
L'utilisation de robots.txt indique aux moteurs de recherche quelles pages explorer et lesquelles éviter complètement , ce qui optimise l'efficacité et la fréquence de l'exploration.
2. Gérer le contenu dupliqué
Robots.txt peut vous aider à éviter l'exploration de contenu similaire ou en double sur vos pages.
De nombreux sites Web contiennent une forme de contenu en double - qu'il s'agisse de pages avec des paramètres d'URL, de pages www ou non www, de fichiers PDF identiques, etc.
En pointant ces pages via robots.txt, vous pouvez gérer le contenu qui n'a pas besoin d'être exploré et aider le moteur de recherche à n'explorer que les pages que vous souhaitez voir apparaître dans la recherche Google.
3. Empêcher la surcharge du serveur
L'utilisation de robots.txt peut aider à empêcher le serveur du site Web de planter.
De manière générale, Googlebot (et d'autres robots d'exploration respectables) sont généralement bons pour déterminer à quelle vitesse ils doivent explorer votre site Web sans surcharger la capacité de son serveur.
Cependant, vous souhaiterez peut-être bloquer l'accès aux robots d'exploration qui visitent trop et trop souvent votre site.
Dans ces cas, robots.txt peut indiquer aux crawlers sur quelles pages particulières ils doivent se concentrer, laissant les autres parties du site Web seules et empêchant ainsi la surcharge du site.
Ou comme Martin Splitt , le Developer Advocate chez Google l'a expliqué :
“ C'est le taux de crawl, essentiellement combien de stress pouvons-nous mettre sur votre serveur sans planter quoi que ce soit ou souffrir de trop tuer votre serveur. ”
De plus, vous souhaiterez peut-être bloquer certains bots qui causent des problèmes au site - qu'il s'agisse d'un "mauvais" bot surchargeant votre site de requêtes, ou de bloquer les scrapers qui tentent de copier tout le contenu de votre site Web.
Comment fonctionne le fichier robots.txt ?
Les principes fondamentaux du fonctionnement du fichier robots.txt sont assez simples - il se compose de 2 éléments de base qui dictent quel robot d'indexation doit faire quelque chose et ce que cela doit être exactement :
- User-agents : spécifiez quels robots d'exploration seront dirigés pour éviter (ou explorer) certaines pages
- Directives : indique aux agents utilisateurs ce qu'ils doivent faire avec certaines pages.
Voici l'exemple le plus simple de ce à quoi le fichier robots.txt peut ressembler avec ces 2 éléments :
Agent utilisateur : Googlebot Interdire : /wp-admin/
Regardons de plus près les deux.
Agents utilisateurs
User-agent est le nom d'un robot d'exploration spécifique qui recevra des directives sur la manière d'explorer votre site Web.
Par exemple, l'agent utilisateur pour le robot d'exploration général de Google est " Googlebot ", pour le robot d'exploration Bing c'est " BingBot ", pour Yahoo " Slurp ", etc.
Pour marquer tous les types de robots d'exploration Web pour une certaine directive à la fois, vous pouvez utiliser le symbole " * " (appelé joker) - il représente tous les robots qui "obéissent" au fichier robots.txt.
Dans le fichier robots.txt, cela ressemblerait à ceci :
Agent utilisateur : * Interdire : /wp-admin/
Remarque : Gardez à l'esprit qu'il existe de nombreux types d'agents utilisateurs, chacun d'entre eux se concentrant sur l'exploration à des fins différentes.
Si vous souhaitez voir quels user-agents Google utilise, consultez cet aperçu des robots d'exploration Google .
Directives
Les directives Robots.txt sont les règles que l'agent utilisateur spécifié suivra.
Par défaut, les robots d'exploration sont chargés d'explorer toutes les pages Web disponibles - robots.txt spécifie ensuite les pages ou les sections de votre site Web qui ne doivent pas être explorées.
Il y a 3 règles les plus courantes qui sont utilisées :
- " Disallow " - indique aux crawlers de ne pas accéder à tout ce qui est spécifié dans cette directive. Vous pouvez attribuer plusieurs instructions d'interdiction aux agents utilisateurs.
- « Autoriser » - indique aux robots d'exploration qu'ils peuvent accéder à certaines pages de la section de site déjà interdite.
- " Plan du site " - si vous avez configuré un plan du site XML, robots.txt peut indiquer aux robots d'exploration Web où ils peuvent trouver les pages que vous souhaitez explorer en les pointant vers votre plan du site.
Voici un exemple de ce à quoi robots.txt peut ressembler avec ces 3 directives simples :
Agent utilisateur : Googlebot Interdire : /wp-admin/ Autoriser : /wp-admin/random-content.php Plan du site : https://www.example.com/sitemap.xml
Avec la première ligne, nous avons déterminé que la directive s'applique à un robot spécifique - Googlebot.
Dans la deuxième ligne (la directive), nous avons dit à Googlebot que nous ne voulons pas qu'il accède à un certain dossier - dans ce cas, la page de connexion d'un site WordPress.
Dans la troisième ligne, nous avons ajouté une exception : bien que Googlebot ne puisse pas accéder à tout ce qui se trouve sous le /wp-admin/ dossier, il peut visiter une adresse spécifique.
Avec la quatrième ligne, nous avons indiqué à Googlebot où trouver votre Sitemapavec une liste d'URL que vous souhaitez explorer.
Il existe également quelques autres règles utiles qui peuvent être appliquées à votre fichier robots.txt, en particulier si votre site contient des milliers de pages qui doivent être gérées.
* (Caractère générique)
Le caractère générique *est une directive qui indique une règle de correspondance des modèles.
La règle est particulièrement utile pour les sites Web qui contiennent des tonnes de contenu généré, des pages de produits filtrées, etc.
Par exemple, au lieu d'interdire chaque page de produit sous la /products/section individuellement (comme c'est le cas dans l'exemple ci-dessous) :
Agent utilisateur: * Interdire : /produits/chaussures ? Interdire : /products/boots ? Interdire : /produits/baskets ?
Nous pouvons utiliser le caractère générique pour les interdire tous à la fois :
Agent utilisateur: * Interdire : /produits/* ?
Dans l'exemple ci-dessus, l'agent utilisateur est chargé de ne pas explorer de page sous la /products/section contenant le point d'interrogation "?" (souvent utilisé pour les URL de catégories de produits paramétrées).
$
Le $ symbole est utilisé pour indiquer la fin d'une URL - les robots peuvent être informés qu'ils ne doivent pas (ou doivent) explorer les URL avec une certaine fin :
Agent utilisateur: * Interdire : /*.gif$
Le $signe " " indique aux bots qu'ils doivent ignorer toutes les URL qui se terminent par " .gif".
#
Le # signe sert simplement de commentaire ou d'annotation pour les lecteurs humains - il n'a aucun impact sur un agent utilisateur, ni ne sert de directive :
# Nous ne voulons pas qu'un crawler visite notre page de connexion ! Agent utilisateur: * Interdire : /wp-admin/
Comment créer un fichier robots.txt
Créer votre propre fichier robots.txt n'est pas sorcier.
Si vous utilisez WordPress pour votre site, vous aurez déjà créé un fichier robots.txt de base, similaire à ceux présentés ci-dessus.
Cependant, si vous prévoyez d'apporter des modifications supplémentaires à l'avenir, il existe quelques plugins simples qui peuvent vous aider à gérer votre fichier robots.txt, tels que :
Ces plugins facilitent le contrôle de ce que vous souhaitez autoriser et interdire, sans avoir à écrire vous-même une syntaxe compliquée.
Alternativement, vous pouvez également modifier votre fichier robots.txt via FTP - si vous êtes sûr d'y accéder et de le modifier, le téléchargement d'un fichier texte est assez facile.
Cependant, cette méthode est beaucoup plus compliquée et peut rapidement introduire des erreurs.
Conseil : Si vous souhaitez en savoir plus sur le téléchargement du fichier robots.txt sur votre site Web, consultez la documentation de Google sur la création et le téléchargement d'un fichier robots.txt .
Comment vérifier un fichier robots.txt
Il existe de nombreuses façons de vérifier (ou de tester) votre fichier robots.txt - premièrement, vous devriez essayer de trouver robots.txt par vous-même.
Sauf si vous avez indiqué une URL spécifique, votre fichier sera hébergé sur " https://votredomaine.com/robots.txt " - si vous utilisez un autre créateur de site Web, l'URL spécifique peut être différente.
Pour vérifier si les moteurs de recherche comme Google peuvent réellement trouver et "obéir" à votre fichier robots.txt, vous pouvez soit :
- Utilisez robots.txt Tester - un outil simple de Google qui peut vous aider à savoir si votre fichier robots.txt fonctionne correctement.
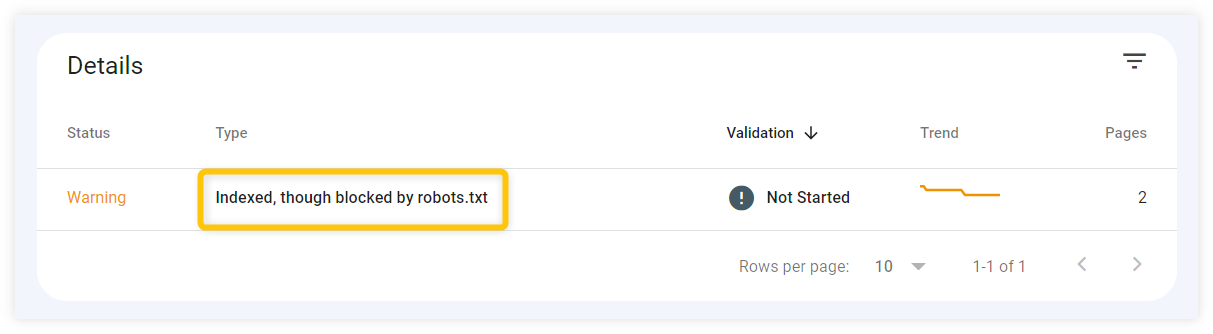
- Vérifiez Google Search Console - vous pouvez rechercher toutes les erreurs causées par robots.txt dans l'onglet " Couverture " de Google Search Console. Assurez-vous qu'aucune URL ne signale des messages « bloqués par robots.txt » par inadvertance.
Bonnes pratiques Robots.txt
Les fichiers Robots.txt peuvent facilement devenir complexes, il est donc préférable de garder les choses aussi simples que possible.
Voici quelques conseils qui peuvent vous aider à créer et à mettre à jour votre propre fichier robots.txt :
- Utilisez des fichiers séparés pour les sous-domaines - si votre site Web comporte plusieurs sous-domaines, vous devez les traiter comme des sites Web distincts. Créez toujours des fichiers robots.txt séparés pour chaque sous-domaine que vous possédez.
- Spécifiez les agents utilisateurs une seule fois - essayez de fusionner toutes les directives affectées à un agent utilisateur spécifique. Cela établira la simplicité et l'organisation de votre fichier robots.txt.
- Assurez-vous de la spécificité - assurez-vous de spécifier les chemins d'URL exacts et faites attention aux barres obliques ou aux signes spécifiques présents (ou absents) dans vos URL.
Aucun commentaire:
Enregistrer un commentaire