Exploration et indexation : comment Google voit-il et stocke-t-il vos pages ?
C'est quoi Le crawl ?
Le crawl est un processus qui permet aux moteurs de recherche de découvrir de nouveaux contenus sur Internet. Pour ce faire, ils utilisent des robots d'exploration qui suivent les liens des pages Web déjà connues vers les nouvelles.
Étant donné que des milliers de pages Web sont produites ou mises à jour chaque jour, le processus d'exploration est un mécanisme sans fin répété encore et encore.
Martin Splitt, Google Webmaster Trend Analyst, décrit le processus d'exploration très simplement :
«Nous commençons quelque part avec certaines URL, puis suivons essentiellement les liens à partir de là. Donc, nous rampons essentiellement sur Internet (une) page par page, plus ou moins.
L'exploration est la toute première étape du processus. Elle est suivie par l'indexation, le classement (pages passant par divers algorithmes de classement) et enfin, la diffusion des résultats de recherche.
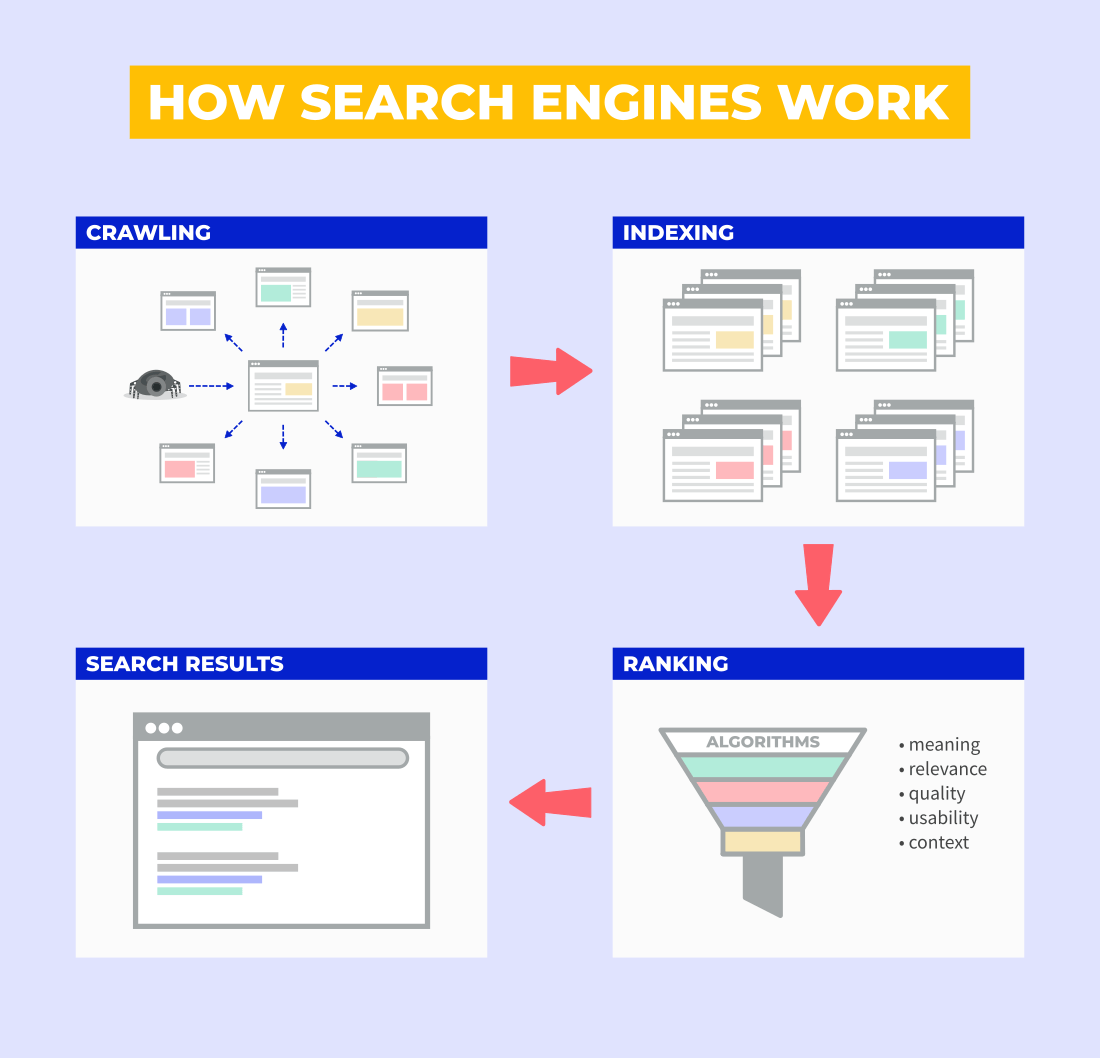
Allons un peu plus loin ici et regardons comment fonctionne le crawl.
Qu'est-ce qu'un robot d'exploration de moteur de recherche ?
Le robot d'exploration des moteurs de recherche (également appelé araignée Web ou robot d'exploration) est un programme qui explore les pages Web, analyse leur contenu et collecte les données à des fins d'indexation.
Chaque fois qu'un crawler visite une nouvelle page Web via un lien hypertexte, il examine le contenu qu'elle contient - scannant tout le texte, les éléments visuels, les liens, les fichiers HTML, CSS ou JavaScript, etc. - puis transmet (ou récupère) ces informations pour traitement et indexation éventuelle.
Google, en tant que moteur de recherche, utilise son propre robot d'indexation appelé Googlebot. Il existe 2 grands types de crawlers :
- Googlebot Smartphone – robot d'exploration principal
- Googlebot Desktop – robot d'exploration secondaire
Googlebot préfère explorer les sites Web principalement comme un navigateur de smartphone , mais il peut également explorer à nouveau chaque page Web avec son robot d'exploration de bureau pour vérifier les performances et le comportement du site Web des deux points de vue.
La fréquence de crawl des nouvelles pages est déterminée par le budget de crawl.
Qu'est-ce qu'un budget de crawl ?
Le budget de crawl détermine la quantité et la fréquence de crawl effectuées par les robots d'indexation. En d'autres termes, il dicte le nombre de pages qui seront explorées et la fréquence à laquelle ces pages seront explorées à nouveau par Googlebot.
Le budget de crawl est déterminé par 2 facteurs principaux :
- Limite du taux d'exploration - le nombre de pages pouvant être explorées simultanément sur le site Web sans surcharger son serveur.
- Demande d'exploration : le nombre de pages qui doivent être explorées et/ou réexplorées par Googlebot.
Le budget de crawl devrait être principalement une préoccupation pour les grands sites Web avec des millions de pages Web, pas pour les petits sites qui ne contiennent que quelques centaines de pages.
De plus, avoir un gros budget de crawl n'apporte pas forcément d'avantages supplémentaires à un site web puisque ce n'est pas un signal de qualité pour les moteurs de recherche.
Qu'est-ce que l'indexation ?
L'indexation est un processus d'analyse et de stockage du contenu des pages Web explorées dans la base de données (également appelée index). Seules les pages indexées peuvent être classées et utilisées dans les requêtes de recherche pertinentes.
Chaque fois qu'un robot d'exploration découvre une nouvelle page Web, Googlebot transmet son contenu (par exemple, du texte, des images, des vidéos, des méta-tags, des attributs, etc.) dans la phase d'indexation où le contenu est analysé pour une meilleure compréhension du contexte et stocké dans le indice.
Martin Splitt explique ce que fait réellement l'étape d'indexation :
« Une fois qu'on a ces pages (…) on a besoin de les comprendre. Nous devons comprendre en quoi consiste ce contenu et à quoi il sert. Alors c'est la deuxième étape, qui est l'indexation.
Pour ce faire, Google utilise le soi-disant système d'indexation de la caféine qui a été introduit en 2010.
La base de données d'un index Caffeine peut stocker des millions et des millions de gigaoctets de pages Web. Ces pages sont systématiquement traitées et indexées (et recrawlées) par Googlebot en fonction du contenu qu'elles contiennent.
Googlebot visite non seulement les sites Web par crawler mobile en premier, mais il préfère également indexer le contenu présent sur leurs versions mobiles depuis la mise à jour dite de Mobile-First Indexing .
Qu'est-ce que l'indexation Mobile-First ?
L'indexation mobile First a été introduite pour la première fois en 2016 lorsque Google a annoncé qu'elle indexerait et utiliserait principalement le contenu disponible sur la version mobile du site Web.
La déclaration officielle de Google indique clairement :
"Dans l'indexation mobile d'abord, nous n'obtiendrons les informations de votre site qu'à partir de la version mobile, alors assurez-vous que Googlebot peut voir le contenu complet et toutes les ressources qui s'y trouvent."
Étant donné que la plupart des gens utilisent des téléphones portables pour naviguer sur Internet aujourd'hui, il est logique que Google veuille regarder les sites Web "de la même manière" que les gens. Il s'agit également d'un appel clair aux propriétaires de sites Web pour qu'ils s'assurent que leurs sites Web sont réactifs et adaptés aux mobiles.
Remarque : Il est important de réaliser que l'indexation mobile d'abord ne signifie pas nécessairement que Google n'explorera pas les sites Web avec son agent de bureau (Googlebot Desktop) pour comparer le contenu des deux versions.
À ce stade, nous avons couvert le concept d'exploration et d'indexation d'un point de vue théorique.
Examinons maintenant les étapes concrètes que vous pouvez effectuer en ce qui concerne l'exploration et/ou l'indexation de votre site Web.
Comment faire en sorte que Google crawle et indexe votre site Web ?
En ce qui concerne l'exploration et l'indexation réelles, il n'y a pas de "commande directe" qui obligerait les moteurs de recherche à indexer votre site Web.
Cependant, il existe plusieurs façons d'influencer si, quand et comment votre site Web sera exploré et indexé.
Voyons donc quelles sont vos options lorsqu'il s'agit de "dire à Google votre existence".
1. Ne rien faire – approche passive
D'un point de vue technique, vous n'avez rien à faire pour que votre site Web soit exploré et indexé par Google.
Tout ce dont vous avez besoin est un lien du site Web externe et Googlebot commencera éventuellement à explorer et à indexer toutes les pages disponibles.
Cependant, adopter une approche « ne rien faire » peut entraîner un retard dans l'exploration et l'indexation de vos pages, car cela peut prendre un certain temps à un robot d'exploration Web pour découvrir votre site Web.
2. Soumettre des pages Web via l'outil d'inspection d'URL
L'un des moyens de "sécuriser" l'exploration et l'indexation de pages Web individuelles consiste à demander directement à Google d'indexer (ou de réindexer) vos pages à l'aide de l'outil d'inspection d'URL de Google Search Console.
Cet outil est pratique lorsque vous avez une toute nouvelle page ou que vous avez apporté des modifications substantielles à votre page existante et que vous souhaitez l'indexer dès que possible.
Le processus est assez simple :
1. Accédez à Google Search Console et insérez votre URL dans la barre de recherche en haut. Cliquez sur entrer.
2. La Search Console vous montrera l'état de la page. S'il n'est pas indexé, vous pouvez demander l'indexation. Si elle est indexée, vous n'avez rien à faire ni à demander à nouveau (si vous avez apporté des modifications plus importantes à la page).
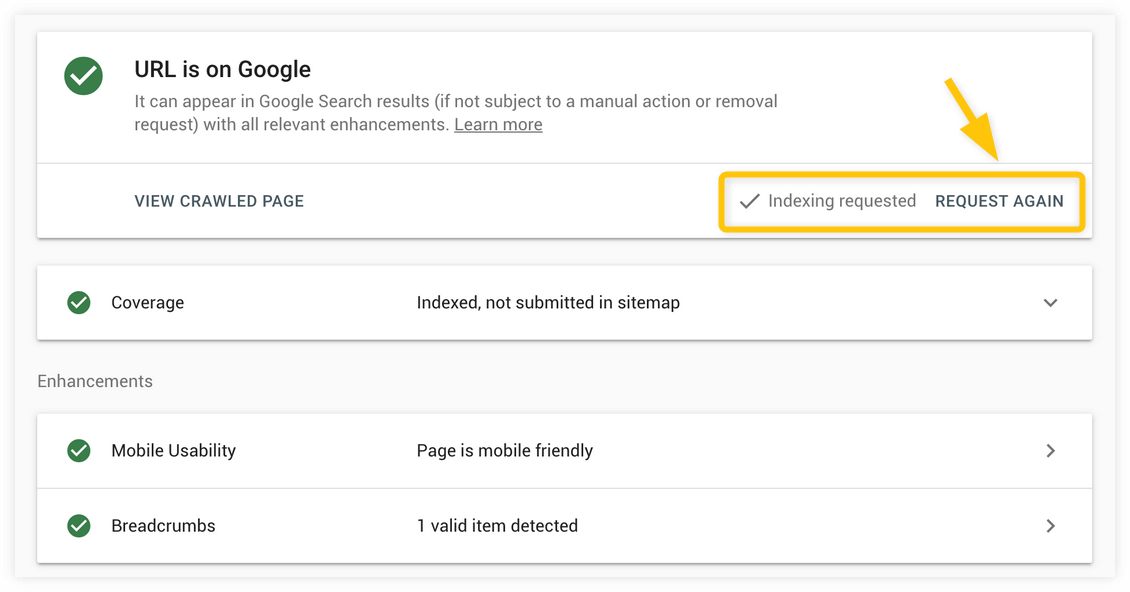
3. L'outil d'inspection d'URL commencera à tester si la version en direct de l'URL peut être indexée (cela peut prendre quelques secondes ou minutes).
4. Une fois le test effectué avec succès, une notification apparaîtra, confirmant que votre URL a été ajoutée à une file d'attente d'exploration prioritaire pour l'indexation. Le processus d'indexation peut prendre de quelques minutes à plusieurs jours.
Remarque : Cette méthode d'indexation est recommandée pour quelques pages Web ; n'abusez pas de cet outil si vous avez un grand nombre d'URL que vous souhaitez indexer.
La demande d'indexation ne garantit pas nécessairement que votre URL sera indexée. Si l'URL est bloquée pour l'exploration et/ou l'indexation ou présente des problèmes de qualité qui sont en contradiction avec les directives de qualité de Google, l'URL peut ne pas être indexée du tout.
3. Soumettre un plan du site
Un sitemap est une liste ou un fichier au format XML qui contient toutes vos pages Web que vous avez l'intention d'explorer et d'indexer par le moteur de recherche.
Le principal avantage des sitemaps est qu'il est beaucoup plus facile pour un moteur de recherche d'explorer votre site Web. Vous pouvez soumettre un grand nombre d'URL à la fois et ainsi accélérer le processus d'indexation global de votre site Web.
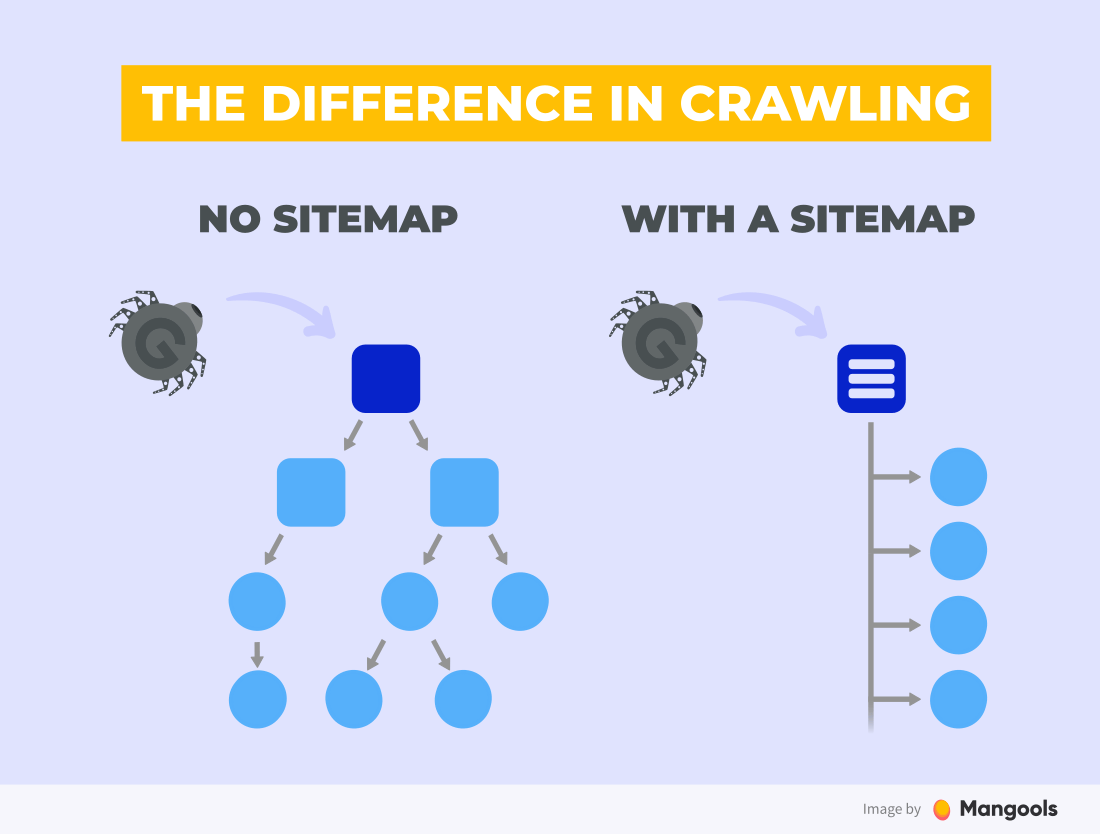
Pour informer Google de votre sitemap, vous utiliserez à nouveau Google Search Console.
Remarque : Le moyen le plus simple de créer un sitemap pour votre site Web WordPress est d'utiliser le plugin Yoast SEO qui le fera automatiquement pour vous. Consultez ce guide pour savoir comment trouver l'URL de votre sitemap.
Allez ensuite dans Google Search Console > Sitemaps et collez l'URL de votre sitemap sous Add a new sitemap :
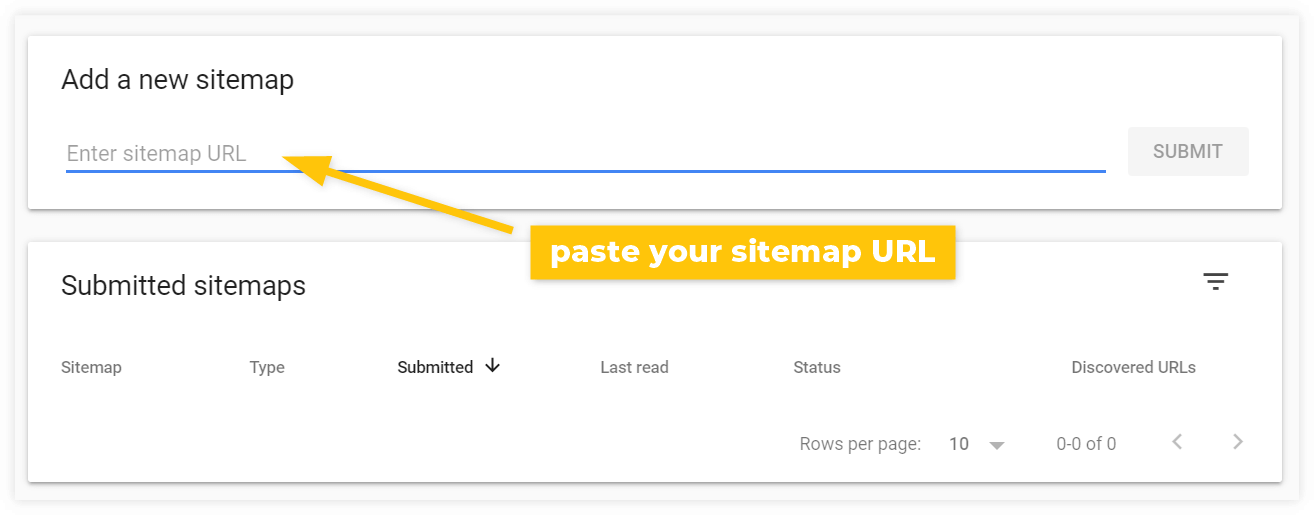
Après la soumission, Googlebot vérifiera éventuellement votre sitemap et explorera toutes les pages Web répertoriées que vous avez fournies (en supposant qu'elles ne sont pas empêchées d'explorer et d'indexer de quelque manière que ce soit).
4. Faites des liens internes appropriés
Une structure de liens internes solide est une excellente approche à long terme pour faciliter l'exploration de vos pages Web.
Comment faire ça? La réponse est une architecture plate de site Web . Autrement dit, avoir toutes les pages à moins de 3 liens les unes des autres :
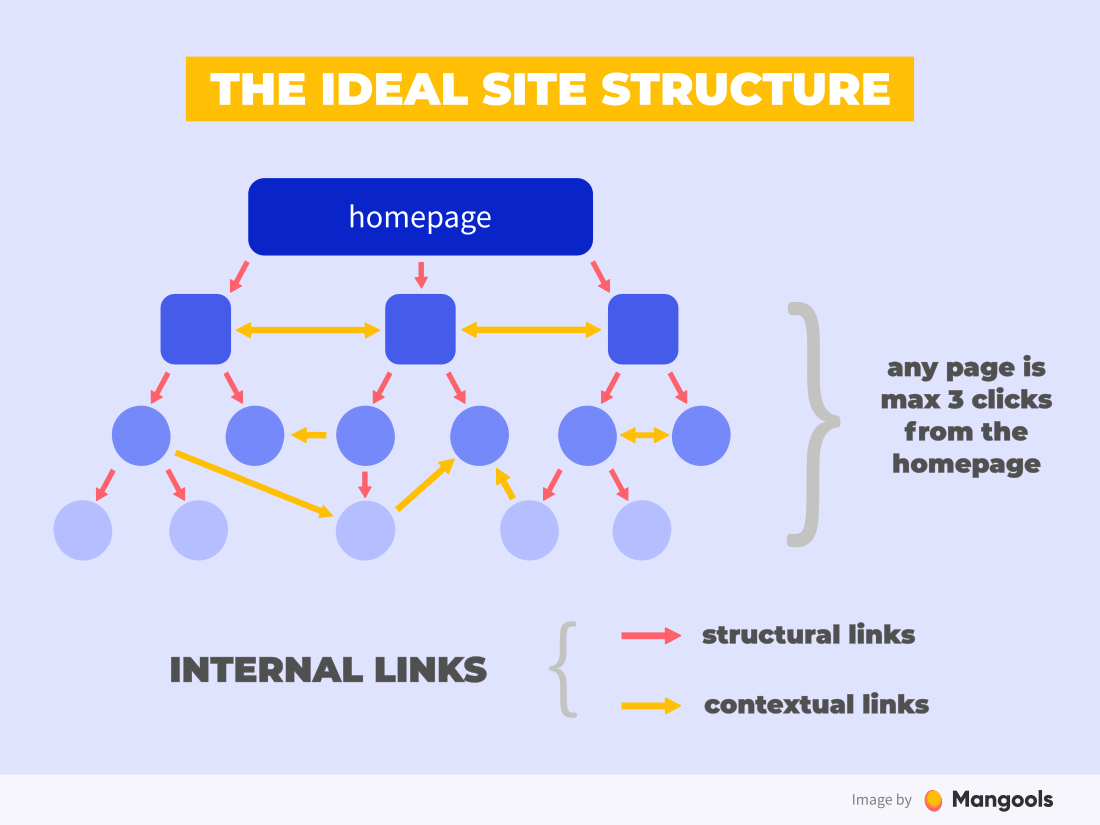
Une bonne architecture de liaison peut sécuriser l'exploration de toutes les pages Web que vous souhaitez indexer, car les robots d'exploration Web auront facilement accès à chacune d'entre elles. Cette pratique est particulièrement importante pour les grands sites (par exemple e-commerce) qui contiennent des milliers de pages avec des produits.
Conseil : les liens internes sont importants, mais vous devez également viser à obtenir des liens externes solides et pertinents à partir de sites Web de haute autorité. Cela peut entraîner une exploration et une indexation régulières ainsi qu'un classement plus élevé dans les SERP pertinents.
Comment empêcher Google de crawler et d'indexer votre page ?
Il existe de nombreuses raisons pour empêcher Googlebot d'explorer et/ou d'indexer des parties de votre site Web. Par example:
- Contenu privé (par exemple, les informations de l'utilisateur qui ne doivent pas apparaître dans les résultats de recherche)
- Pages Web en double (par exemple, des pages avec le même contenu qui ne doivent pas être explorées pour économiser le budget d'exploration et/ou apparaître plusieurs fois dans les résultats de recherche)
- Pages vides ou d'erreur (par exemple, les pages de travail en cours qui ne sont pas préparées pour être indexées et affichées dans les résultats de recherche)
- Pages sans valeur ou sans valeur (par exemple, les pages générées par les utilisateurs qui n'apportent aucun contenu de qualité pour les requêtes de recherche).
À ce stade, il devrait être clair que Googlebot est très efficace lorsqu'il s'agit de découvrir de nouvelles pages Web, même lorsque ce n'était pas dans votre intention.
Comme l' indique Google : "Il est presque impossible de garder un serveur Web secret en ne publiant pas de liens vers celui-ci."
Examinons nos options en matière de prévention de l'exploration et/ou de l'indexation.
1. Utilisez robots.txt (pour empêcher l'exploration)
Robots.txt est un petit fichier texte qui contient des commandes directes pour les robots d'indexation sur la façon dont ils doivent explorer votre site Web.
Chaque fois que les robots d'exploration Web visitent votre site Web, ils vérifient d'abord si votre site Web contient le fichier robots.txt et quelles sont les instructions pour eux. Après avoir lu les commandes du fichier, ils commencent à explorer votre site Web selon les instructions.
En utilisant les directives « autoriser » et « interdire » dans le fichier robots.txt, vous pouvez indiquer aux robots d'exploration Web quelles parties du site Web doivent être visitées et explorées et quelles pages Web ne doivent pas être modifiées.
Voici un exemple du fichier robots.txt du site Web du New York Times avec de nombreuses commandes d'interdiction :
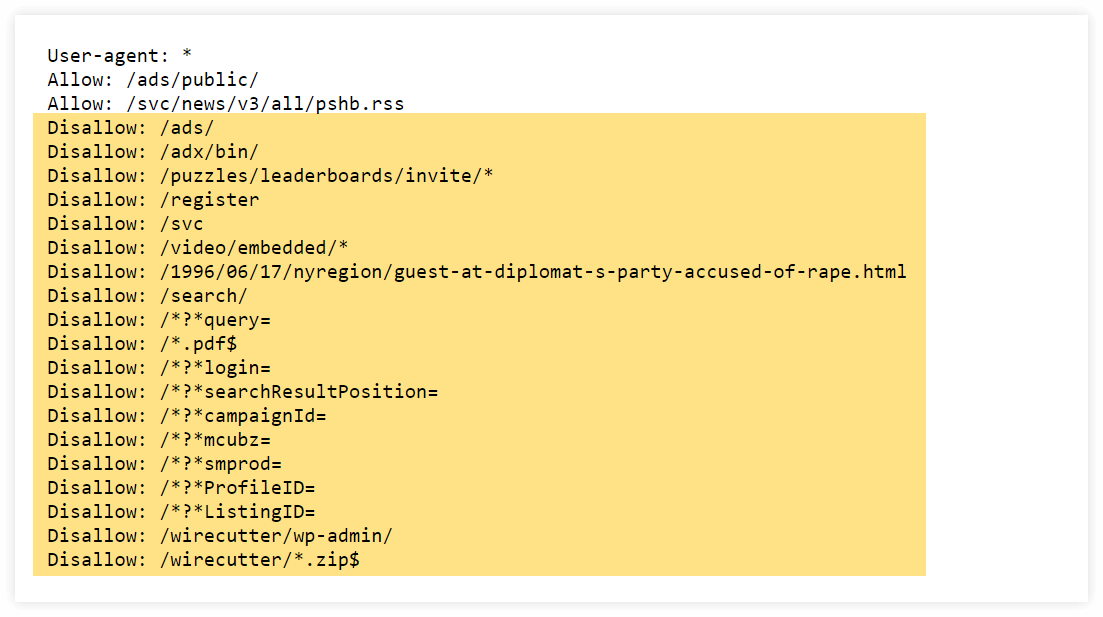
Par exemple, vous pouvez empêcher Googlebot d'explorer :
- pages avec du contenu dupliqué
- pages privées
- URL avec paramètres de requête
- pages avec un contenu léger
- pages d'essai
Sans les instructions de ce fichier, le robot d'exploration Web visiterait toutes les pages Web qu'il peut trouver, y compris les URL que vous souhaitez éviter d'être explorées.
Bien que robots.txt puisse être un bon moyen d'empêcher Googlebot d'explorer vos pages, vous ne devez pas vous fier à cette méthode pour masquer le contenu.
Les pages Web non autorisées peuvent toujours être indexées par Google si d'autres sites Web pointent des liens vers ces URL.
Pour empêcher l'indexation des pages Web, il existe une autre méthode, plus efficace, les Robots Meta Directives.
2. Utilisez la directive "noindex" (pour empêcher l'indexation)
Les directives méta du robot (parfois appelées balises méta) sont de petits morceaux de code HTML placés dans la section <head> d'une page Web qui indiquent aux moteurs de recherche comment indexer ou explorer cette page.
L'une des directives les plus courantes est la directive dite "noindex" (une méta directive robot avec la valeur noindex dans l' attribut content ). Il empêche les moteurs de recherche d'indexer et d'afficher votre page Web dans les SERP.
Il ressemble à ceci :
<meta name="robots" content="noindex">
L'attribut "robots" signifie que la commande s'applique à tous les types de robots d'exploration Web.
La directive noindex est particulièrement utile pour les pages destinées à être vues par les visiteurs, mais vous ne voulez pas qu'elles soient indexées ou qu'elles apparaissent dans les résultats de recherche.
Le noindex est généralement combiné avec les attributs follow ou nofollow pour indiquer aux moteurs de recherche s'ils doivent explorer les liens de la page.
Important : Vous ne devez pas utiliser à la fois la directive noindex et le fichier robots.txt pour empêcher les robots d'exploration Web d'accéder à votre page.
Comme Google l'a clairement indiqué :
« Pour que la directive noindex soit efficace, la page ne doit pas être bloquée par un fichier robots.txt. Si la page est bloquée par un fichier robots.txt, le robot d'exploration ne verra jamais la directive noindex et la page peut toujours apparaître dans les résultats de recherche, par exemple si d'autres pages y renvoient.
Comment vérifier si la page est indexée ?
Lorsqu'il s'agit de vérifier si les pages Web sont explorées et indexées ou si une page Web particulière présente des problèmes, il existe quelques options.
1. Vérifiez-le manuellement
Le moyen le plus simple de vérifier si votre site Web a été indexé ou non est de le faire manuellement en utilisant l' opérateur site : :
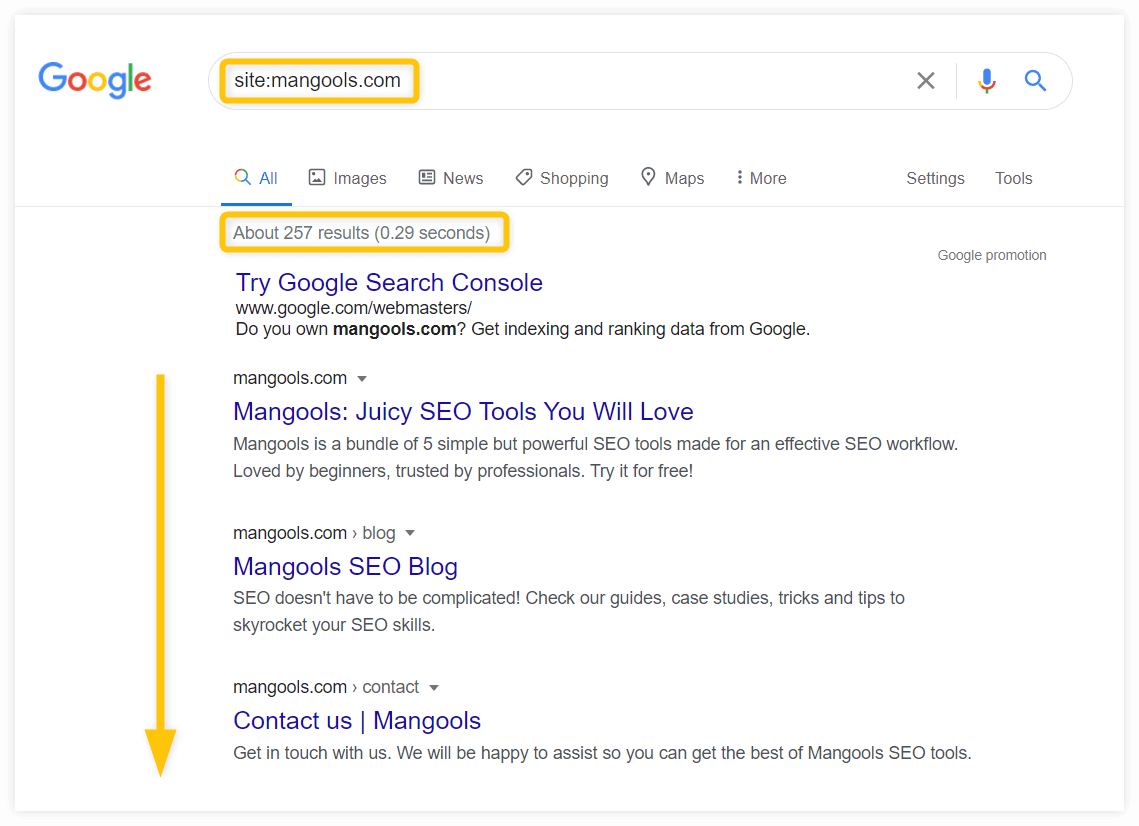
Si votre site Web a été exploré et indexé, vous devriez voir toutes les pages indexées ainsi que le nombre approximatif de pages indexées dans la section "À propos des résultats XY" .
Si vous souhaitez vérifier si une URL spécifique a été indexée, utilisez l'URL au lieu du domaine :
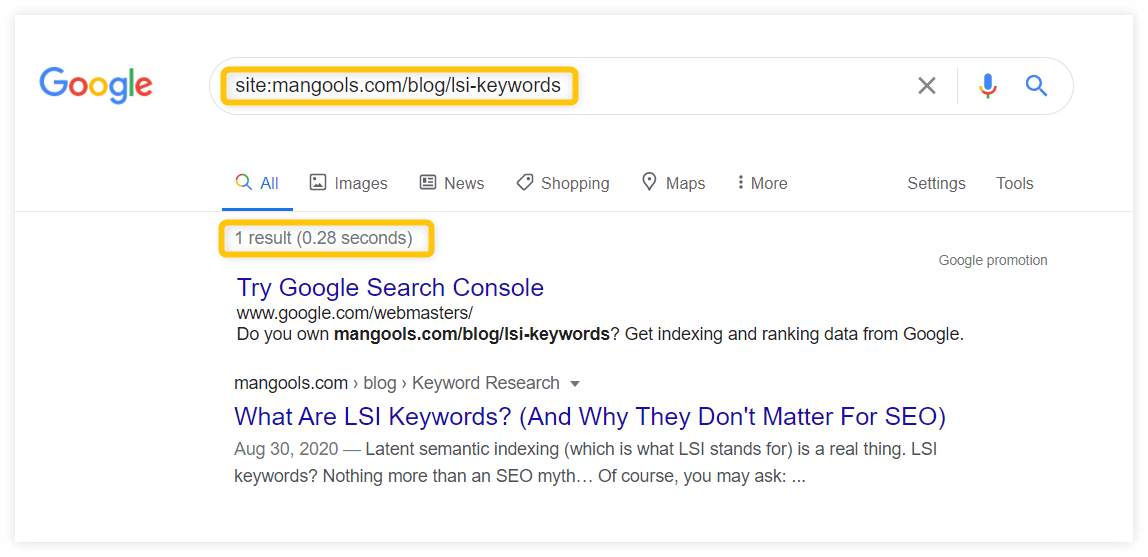
Si votre page Web a été indexée, vous devriez la voir dans les résultats de recherche.
2. Vérifiez l'état de la couverture de l'index
Pour obtenir un aperçu plus détaillé de vos pages indexées (ou non indexées), vous pouvez utiliser le rapport de couverture de l'index dans Google Search Console.
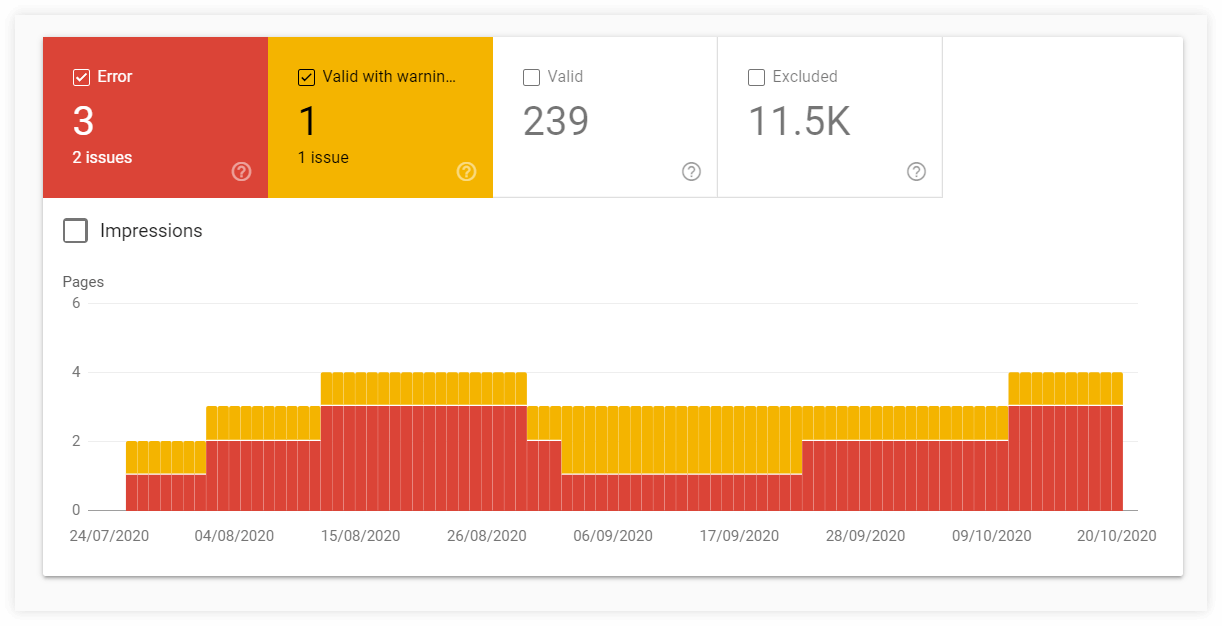
Les graphiques avec des détails dans le rapport de couverture de l'index peuvent fournir des informations précieuses sur les statuts des URL et les types de problèmes avec les pages explorées et/ou indexées.
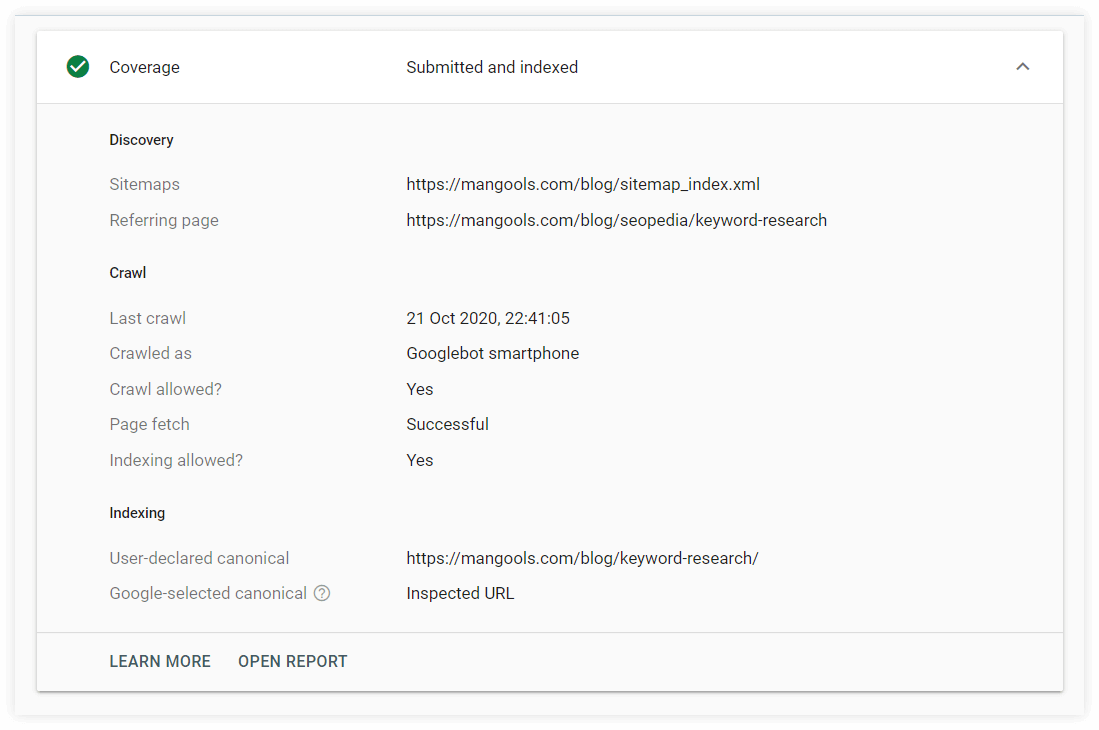
3. Utilisez l'outil d'inspection d'URL
L'outil d'inspection d'URL peut fournir des informations sur les pages Web individuelles de votre site Web depuis la dernière fois qu'elles ont été explorées.
Vous pouvez vérifier si votre page Web :
- a quelques problèmes (avec des détails sur la façon dont il a été découvert)
- a été exploré et la dernière fois qu'il a exploré
- si la page est indexée et peut apparaître dans les résultats de recherche
Aucun commentaire:
Enregistrer un commentaire